In the modern enterprise, data has rapidly emerged as the new oil, the most valuable commodity driving innovation, competitive advantage, and strategic decision-making. However, the sheer volume, velocity, and variety of information generated daily often overwhelm traditional data management systems. This is where Data Lakes enter the scene—a revolutionary architectural paradigm designed to store, manage, and analyze vast quantities of raw, multi-structured data at scale. Far more than just a massive storage repository, a Data Lake acts as a centralized hub, enabling organizations to unlock profound, otherwise hidden, insights from their entire data estate. It’s the ultimate key to transforming raw information into actionable intelligence, truly unleashing massive insights that power growth and drive future strategies.
The Evolution of Data Storage: From Warehouses to Lakes
To fully appreciate the transformative power of Data Lakes, it’s crucial to understand their historical context within the evolution of data management, particularly in contrast to their predecessors.
A. Traditional Databases: Structured and Relational
For decades, the bedrock of enterprise data management was the traditional relational database.
- Transactional Systems (OLTP): These databases (e.g., SQL Server, Oracle, MySQL) were optimized for online transaction processing (OLTP), handling rapid, consistent, and structured data entry and retrieval for operational applications like customer relationship management (CRM) or enterprise resource planning (ERP). They enforced strict schemas and data integrity.
- Strict Schemas: Data had to conform to a predefined, rigid structure (schema-on-write) before being stored. This ensured data quality but made it inflexible for new data types or rapid changes.
- Limitations for Analytics: While excellent for transactional queries, these databases were not designed for complex analytical queries across large datasets. Running analytical queries directly on OLTP databases could impact operational performance.
B. Data Warehouses: The Rise of Business Intelligence
To address the limitations of transactional databases for analytical purposes, Data Warehouses emerged in the 1990s.
- Purpose-Built for Analytics (OLAP): Data warehouses (e.g., Teradata, Netezza, early versions of Snowflake/Redshift) were specifically designed for Online Analytical Processing (OLAP). They aggregated, cleansed, and transformed structured data from various operational sources into a unified schema, making it ready for business intelligence (BI) and reporting.
- Schema-on-Write and ETL: Data was heavily processed and transformed (Extract, Transform, Load – ETL) before being loaded into the warehouse. This meant a clean, standardized dataset, but it was time-consuming, expensive, and inflexible for new data sources.
- Structured Data Focus: Data warehouses were primarily optimized for structured, relational data. Handling semi-structured (e.g., JSON, XML) or unstructured data (e.g., text, images, video) was challenging or impossible.
- Cost and Scalability: As data volumes grew, scaling traditional data warehouses became prohibitively expensive, requiring specialized hardware and complex tuning.
C. The Big Data Era and the Need for Lakes
The explosion of new data sources (web logs, social media, IoT sensors), coupled with the rise of affordable distributed storage and computing (Hadoop), exposed the limitations of data warehouses, giving rise to the Data Lake concept.
- Volume, Velocity, Variety (3 Vs of Big Data):
- Volume: Data generated reached petabytes and exabytes, overwhelming traditional systems.
- Velocity: Data arrived at unprecedented speeds (e.g., real-time sensor data, clickstreams), demanding continuous ingestion.
- Variety: Data came in all forms—structured (databases), semi-structured (JSON, XML, logs), and unstructured (images, video, audio, text).
- Schema-on-Read: A fundamental shift. Data is stored in its raw, original format without prior transformation. The schema is applied at the time of analysis (schema-on-read), providing immense flexibility.
- Cost-Effective Storage: Leveraging distributed file systems (like HDFS) and object storage (like AWS S3, Azure Blob Storage, Google Cloud Storage) makes storing vast amounts of raw data significantly cheaper than in a data warehouse.
- Enabling New Analytics: By retaining raw data, Data Lakes enable advanced analytics techniques like machine learning, AI, and predictive modeling, which often require raw, untransformed data to discover novel patterns.
This evolution showcases a clear trend: from highly rigid, structured data systems to flexible, scalable repositories capable of handling any data, any time, for any analytical purpose.
Core Components and Characteristics of a Modern Data Lake
A modern Data Lake is far more than just a storage bucket; it’s a sophisticated, integrated architecture designed for massive scale and diverse analytical workloads.
A. Ingestion Layer: Handling Diverse Data Sources
The ingestion layer is responsible for bringing data into the Data Lake from a multitude of sources, often handling different formats and velocities.
- Batch Ingestion: For large volumes of historical or periodically updated data (e.g., daily sales reports, nightly database dumps). Tools like Apache NiFi, AWS Glue, Azure Data Factory, or custom scripts.
- Real-time/Streaming Ingestion: For continuous, high-velocity data streams (e.g., IoT sensor data, website clickstreams, social media feeds). Tools like Apache Kafka, Amazon Kinesis, Azure Event Hubs, Google Cloud Pub/Sub.
- Diverse Connectors: Ability to connect to various data sources: relational databases, NoSQL databases, SaaS applications, APIs, file systems, streaming platforms.
B. Storage Layer: Raw, Scalable, Cost-Effective
This is the central repository where all data, regardless of its structure, is stored.
- Raw Data Format: Data is stored in its original, untransformed state, preserving all its richness and allowing for future analysis without loss of detail.
- Object Storage: Cloud-native object storage services (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage) are the preferred choice due to their massive scalability, high durability, cost-effectiveness, and native integration with big data tools.
- Distributed File Systems: For on-premise or hybrid setups, distributed file systems like HDFS (Hadoop Distributed File System) are used to store data across a cluster of commodity servers.
- Schema-on-Read: The defining feature. Data does not need a predefined schema upon ingestion. The schema is applied dynamically by analytical tools when the data is read and queried. This provides extreme flexibility.
- Data Tiering: Often, data is tiered based on access frequency and retention policies (e.g., hot storage for frequently accessed data, cold/archival storage for rarely accessed historical data) to optimize costs.
C. Processing Layer: Transforming and Preparing Data
Once data is in the lake, it needs to be processed, cleansed, and transformed for various analytical purposes. This is where the schema-on-read happens.
- Batch Processing: For large-scale data transformations that run periodically. Frameworks like Apache Spark, Hadoop MapReduce, Apache Hive, or cloud-native services (e.g., AWS Glue, Azure Databricks, Google Cloud Dataflow).
- Stream Processing: For real-time transformations and analytics on data streams. Tools like Apache Flink, Spark Streaming, Kafka Streams, or cloud services (e.g., AWS Kinesis Data Analytics, Azure Stream Analytics).
- Data Catalog and Metadata Management: Crucial for understanding the raw data. A data catalog stores metadata (data about data)—schema information, data lineage, data quality metrics, business definitions—making data discoverable and usable. Tools like Apache Atlas, AWS Glue Data Catalog, or Collibra.
- Data Quality and Governance: Tools and processes to ensure data accuracy, completeness, consistency, and compliance with regulations (e.g., data masking, data anonymization).
D. Consumption Layer: Empowering Diverse Analytics
This layer provides various interfaces and tools for different user personas to access and analyze the processed data.
- Business Intelligence (BI) Tools: For analysts and business users to create dashboards and reports using structured data (e.g., Tableau, Power BI, Looker).
- Data Science Workbenches: For data scientists to explore raw data, build machine learning models, and perform advanced analytics (e.g., Jupyter notebooks, RStudio, specialized cloud ML platforms like AWS SageMaker, Azure Machine Learning, Google AI Platform).
- SQL Query Engines: For data analysts and developers to query data using familiar SQL syntax, even on unstructured data. Tools like Apache Presto/Trino, Apache Hive, AWS Athena, Google BigQuery, Databricks SQL Analytics.
- NoSQL Access: For applications requiring direct access to semi-structured or unstructured data.
- APIs: For programmatic access to data for custom applications or integrations.
E. Security and Governance Layer: Protecting the Lake
Security, access control, and compliance are paramount across all layers of the Data Lake.
- Access Control: Granular control over who can access what data (role-based access control – RBAC, attribute-based access control – ABAC), often integrated with enterprise identity management.
- Data Encryption: Encrypting data at rest (in storage) and in transit (during processing and transfer).
- Audit Logging: Comprehensive logging of all data access and processing activities for compliance and security monitoring.
- Data Masking/Anonymization: Protecting sensitive data while still allowing it to be used for analytics.
- Compliance Frameworks: Ensuring the Data Lake adheres to industry regulations (e.g., GDPR, HIPAA, PCI DSS).
Transformative Advantages of Leveraging Data Lakes
Adopting a Data Lake architecture offers a multitude of powerful benefits, fundamentally changing how organizations manage data and derive value from it.
A. Unleashing Comprehensive and Deeper Insights
The primary advantage of a Data Lake is its ability to store all data, enabling a holistic view of the business and unlocking unprecedented insights.
- Holistic Data View: By ingesting data from every source (operational, transactional, customer interactions, IoT, social media, external feeds), organizations gain a complete, 360-degree view of their operations, customers, and market.
- Discovery of Hidden Patterns: Retaining raw, untransformed data allows data scientists to explore information without predefined notions, discovering patterns, correlations, and anomalies that might be lost in pre-aggregated or transformed data warehouse schemas.
- Advanced Analytics and AI/ML: Data Lakes are the ideal foundation for advanced analytical techniques, especially machine learning and artificial intelligence. AI models often require massive, diverse datasets in their raw form for optimal training and predictive accuracy.
- Faster Time to Insight: While ETL for data warehouses can take months, Data Lakes allow for rapid ingestion and flexible analysis, significantly reducing the time from data acquisition to actionable insight.
B. Extreme Scalability and Unmatched Flexibility
Data Lakes are designed to handle growth and change, offering unparalleled scalability and flexibility.
- Massive Data Volumes: Built on distributed storage (like object storage), Data Lakes can scale to store petabytes and even exabytes of data economically, accommodating exponential data growth without performance degradation.
- Any Data, Any Format: The schema-on-read approach provides immense flexibility, allowing organizations to ingest structured, semi-structured, and unstructured data without prior modeling. This adapts to new data sources easily.
- Agile Data Exploration: Data scientists can rapidly iterate on data models and hypotheses, without waiting for lengthy ETL processes or schema modifications, accelerating experimentation and discovery.
- Future-Proofing Data Assets: By storing raw data, organizations are prepared for future, currently unknown, analytical requirements or technologies. Data that seems irrelevant today might become critical for AI models tomorrow.
C. Significant Cost Efficiency
Compared to traditional data warehouses, Data Lakes can offer substantial cost savings, particularly at scale.
- Lower Storage Costs: Leveraging commodity hardware for HDFS or highly optimized cloud object storage tiers makes storing vast amounts of raw data much cheaper per gigabyte than in enterprise data warehouses.
- Reduced ETL Costs: The schema-on-read approach minimizes the need for extensive, up-front ETL processes, saving on specialized tooling, compute resources, and engineering time associated with data transformation.
- Optimized Compute Usage: Compute resources for processing and analytics can be provisioned on demand in the cloud, scaling up or down as needed, rather than maintaining expensive, constantly running data warehouse servers.
- Flexible Tooling: Data Lakes often support a wide array of open-source and cloud-native tools, allowing organizations to choose cost-effective solutions tailored to specific workloads.
D. Enhanced Collaboration and Data Democratization
Data Lakes facilitate greater access and collaboration among different user roles within an organization.
- Single Source of Truth: By consolidating all enterprise data in one place, Data Lakes reduce data silos and provide a unified view, improving consistency and reducing data discrepancies across departments.
- Empowering Diverse Users: Data Lakes cater to various user personas—BI analysts, data scientists, machine learning engineers, and developers—providing them with the appropriate tools and access methods for their specific needs.
- Improved Data Governance and Trust: Centralized governance, metadata management, and security controls across a single lake improve data quality, trust, and compliance, making data assets more reliable for everyone.
E. Accelerated Business Agility and Innovation
The capabilities unlocked by Data Lakes directly translate into increased business agility and the ability to innovate faster.
- Rapid Experimentation: Data scientists can quickly test new hypotheses, build prototypes, and develop new analytical models using the vast, readily available raw data, accelerating innovation cycles.
- Faster Response to Market Changes: By providing real-time insights and enabling rapid data analysis, Data Lakes empower businesses to quickly understand market shifts, customer behavior changes, or emerging trends, allowing for swift, data-driven strategic adjustments.
- New Product and Service Development: The ability to discover novel insights and build predictive models directly supports the development of new data-driven products, services, and revenue streams.
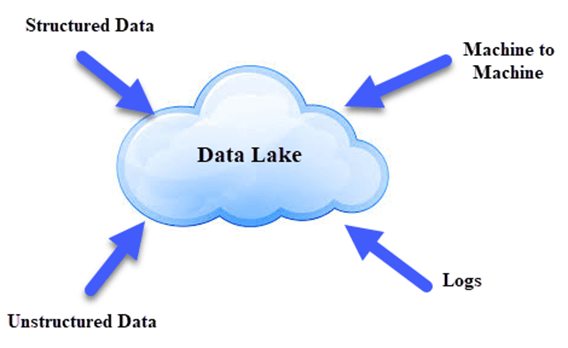
Challenges and Considerations in Implementing a Data Lake
While Data Lakes offer profound benefits, their implementation is not without complexities and potential pitfalls. Organizations must be aware of these challenges to ensure successful adoption.
A. Data Governance and Management Complexity
The sheer volume and variety of data in a Data Lake can quickly lead to a ‘data swamp’ if not properly governed.
- Lack of Metadata Management: Without a robust data catalog and metadata management, users struggle to find relevant data, understand its origin, quality, or meaning, turning the lake into an unusable swamp.
- Data Quality Control: Ingesting raw data means also ingesting dirty data. Establishing processes for data cleansing, validation, and ensuring data quality is crucial, often performed in a ‘curated’ zone of the lake.
- Schema Evolution: While schema-on-read offers flexibility, managing evolving implicit schemas as data sources change requires careful planning and tooling to ensure consistency for consumption.
- Regulatory Compliance: Ensuring compliance with data privacy regulations (e.g., GDPR, HIPAA, CCPA) across diverse, raw datasets, especially for sensitive information, adds significant governance complexity (e.g., data masking, data retention policies).
B. Security and Access Control
Storing all enterprise data, including sensitive information, in a single repository makes security paramount and complex.
- Granular Access Control: Implementing fine-grained access controls to ensure that only authorized users or applications can access specific datasets or columns within the lake, especially for multi-tenant environments.
- Data Encryption: Ensuring all data is encrypted at rest and in transit, and managing encryption keys securely.
- Auditability: Comprehensive logging and auditing of all data access and processing activities to meet compliance requirements and detect suspicious behavior.
- Vulnerability Management: Protecting the underlying infrastructure (servers, network, storage) from cyber threats.
C. Skill Gap and Talent Acquisition
Implementing and managing a Data Lake requires specialized skills that are in high demand.
- Big Data Engineering: Expertise in distributed systems, data pipelines, streaming technologies, and various data formats (e.g., Parquet, ORC, Avro).
- Data Science and Machine Learning: Professionals skilled in statistical modeling, machine learning algorithms, and interpreting complex datasets.
- Cloud Expertise: Deep knowledge of cloud-native big data services and their integration for cloud-based Data Lakes. Finding and retaining this talent can be a significant challenge and cost.
D. Tooling Selection and Integration
The Data Lake ecosystem is vast and constantly evolving, with many open-source and commercial tools.
- Complex Ecosystem: Choosing the right combination of ingestion tools, processing engines, storage formats, and consumption layers can be daunting.
- Interoperability: Ensuring seamless integration and compatibility between different tools and services, especially in hybrid or multi-cloud environments.
- Cost Optimization: Managing costs effectively requires optimizing choice of services, scaling strategies, and data tiering, which can be complex.
E. Performance Optimization for Diverse Workloads
While Data Lakes are scalable, optimizing performance for a wide variety of analytical workloads can be challenging.
- Query Optimization: Ensuring fast query performance across massive datasets, especially for ad-hoc queries on raw data, requires careful data partitioning, indexing, and choice of query engines.
- Real-time vs. Batch: Balancing the needs of real-time streaming analytics with large-scale batch processing within the same infrastructure.
- Compute vs. Storage: Optimizing the interplay between compute resources and storage to prevent bottlenecks and ensure efficient data processing.
F. Organizational Adoption and Data Literacy
Even with the best technology, widespread adoption depends on cultural factors.
- Breaking Down Silos: Overcoming resistance from departments that are accustomed to owning their data in silos.
- Data Literacy: Ensuring that business users and decision-makers understand how to interpret and act upon the insights derived from the Data Lake, promoting a data-driven culture.
- Change Management: Managing the organizational change associated with adopting a new data paradigm.
Best Practices for Designing and Implementing a Data Lake
To successfully leverage the power of Data Lakes and mitigate their inherent complexities, organizations should adhere to a set of proven best practices.
A. Define Clear Business Objectives and Use Cases
Before building, clearly articulate the business problems the Data Lake will solve and the specific use cases it will support (e.g., customer churn prediction, supply chain optimization, IoT anomaly detection). A well-defined purpose guides architecture decisions, tool selection, and ensures measurable ROI, preventing the creation of a ‘data swamp.’
B. Implement a Layered Architecture (Zones)
Organize your Data Lake into logical zones to manage data quality, security, and access, promoting data maturity.
- Raw Zone: Ingest all data in its original, immutable format. This is the landing zone.
- Curated/Staging Zone: Apply initial cleansing, profiling, and basic transformations. This data is still flexible but more reliable.
- Trusted/Refined Zone: Highly curated, transformed, and governed data, often structured in optimized formats (e.g., Parquet, ORC) for specific analytical use cases, ready for BI and ML.
- Sandbox Zone: For data scientists to experiment with raw data without impacting production datasets.
This layered approach balances flexibility with usability and governance.
C. Prioritize Robust Data Governance and Metadata Management
Data governance is not optional for Data Lakes; it’s essential to prevent them from becoming data swamps.
- Data Catalog: Implement a comprehensive data catalog (e.g., Apache Atlas, AWS Glue Data Catalog, Collibra) to capture and manage metadata (schemas, data lineage, definitions, data quality metrics) for all datasets. This makes data discoverable and understandable.
- Data Quality Framework: Establish automated processes for data profiling, validation, cleansing, and monitoring data quality as data flows through the lake.
- Data Lineage: Track the origin and transformation history of data (who changed what, when, why) for auditing, debugging, and compliance.
- Data Stewardship: Assign clear ownership and responsibility for data quality and governance to business and technical teams.
D. Implement Comprehensive Security and Access Control
Security must be embedded at every layer of the Data Lake.
- Granular Access Control: Use Role-Based Access Control (RBAC) or Attribute-Based Access Control (ABAC) to ensure only authorized users/applications can access specific data. Integrate with enterprise identity providers.
- Encryption: Encrypt all data at rest (in storage) and in transit (during processing). Implement robust key management.
- Network Segmentation: Isolate the Data Lake components within secure virtual private clouds (VPCs) and use network security groups and firewalls.
- Audit Logging: Enable detailed audit logging of all data access attempts, queries, and administrative actions for security monitoring and compliance.
- Data Masking/Tokenization: Mask or tokenize sensitive data in non-production environments or for users who do not require direct access to raw sensitive information.
E. Leverage Cloud-Native Services for Scalability and Efficiency
For most organizations, building a Data Lake on a public cloud platform offers unparalleled advantages.
- Object Storage: Utilize cloud object storage (S3, Azure Blob, GCS) as the primary storage layer due to its massive scalability, durability, and cost-effectiveness.
- Managed Services: Leverage managed services for ingestion (Kinesis, Event Hubs, Pub/Sub), processing (Glue, Databricks, Dataflow), query engines (Athena, BigQuery, Spark SQL), and machine learning (SageMaker, Azure ML, AI Platform). These abstract away infrastructure management and provide built-in scalability and reliability.
- Serverless Components: Use serverless functions (Lambda, Azure Functions, Cloud Functions) for event-driven data processing tasks.
F. Choose the Right File Formats for Analytics
While raw data is ingested as-is, data processed in the curated and trusted zones should be stored in optimized formats for analytical performance.
- Columnar Formats: Use Parquet or ORC for analytical datasets. These columnar formats compress data efficiently, improve query performance by allowing query engines to read only necessary columns, and are highly compatible with big data processing engines like Spark and Hive.
- Partitioning: Strategically partition data (e.g., by date, region, customer ID) to reduce the amount of data scanned for queries, significantly improving performance and reducing costs.
G. Foster a Data-Driven Culture and Data Literacy
The technology is only as good as its adoption.
- Collaboration: Encourage collaboration between data engineers, data scientists, and business analysts.
- Training and Education: Invest in training programs to enhance data literacy across the organization, enabling users to understand, interpret, and leverage the insights from the Data Lake effectively.
- Community of Practice: Create forums or communities for data professionals to share knowledge, best practices, and challenges.
H. Implement Robust Monitoring and Performance Management
Continuously monitor the health, performance, and cost of your Data Lake.
- Resource Utilization: Monitor compute engine usage, storage consumption, and data transfer rates to identify bottlenecks and optimize resource allocation.
- Query Performance: Track query execution times and identify slow-running queries for optimization.
- Cost Monitoring: Implement granular cost tracking and alerting to manage cloud spending effectively (FinOps practices).
- Data Pipeline Monitoring: Monitor data ingestion and processing pipelines for failures, delays, or data quality issues.
The Future Trajectory of Data Lakes: Towards Intelligent and Governed Data Fabrics
The Data Lake concept is continuously evolving, driven by the increasing sophistication of AI, the need for real-time insights, and stricter data governance requirements.
A. Data Lakehouses: Converging Analytics Paradigms
One of the most significant trends is the rise of the Data Lakehouse architecture.
- Combining Best of Both: Lakehouses aim to combine the cost-effectiveness and flexibility of Data Lakes (storing raw, diverse data) with the structure, data management, and performance of data warehouses.
- Open Formats and Transactional Capabilities: Key technologies like Delta Lake, Apache Iceberg, and Apache Hudi enable data lakes to support ACID (Atomicity, Consistency, Isolation, Durability) transactions, schema evolution, and time travel, bringing data warehouse-like capabilities to open formats on object storage.
- Unified Platform: This allows organizations to run traditional BI workloads, advanced analytics, and machine learning from a single, unified platform without moving data between separate lakes and warehouses.
B. Augmented Data Governance and Data Fabric
Future Data Lakes will be integrated into broader Data Fabric architectures, driven by AI and automation.
- Automated Metadata Discovery: AI-powered tools will automatically discover, profile, and catalog data, extracting metadata and lineage without manual intervention.
- Intelligent Data Quality: AI/ML will continuously monitor data quality, predict data anomalies, and even suggest automated remediation strategies.
- Semantic Layer: A universal semantic layer will provide a consistent business view of data across disparate sources within the Data Lake and beyond, enabling easier data discovery and consumption for business users.
- Automated Policy Enforcement: Policies for security, privacy, and compliance will be automatically detected, applied, and enforced across the entire data fabric, ensuring continuous governance.
C. Real-Time and Streaming-First Architectures
The demand for instant insights will push Data Lakes towards more real-time and streaming-first architectures.
- Continuous Data Ingestion: More emphasis on robust, low-latency streaming ingestion pipelines for immediate processing.
- Real-time Analytics: Advanced stream processing engines and specialized real-time query capabilities will enable immediate analysis of fresh data for operational insights and rapid decision-making.
- Streaming ML: Training and inference of machine learning models directly on real-time data streams for instant predictions and adaptive systems.
D. Data Mesh: Decentralized Data Ownership
For large, complex enterprises, the Data Mesh architectural paradigm is gaining traction.
- Domain-Oriented Ownership: Instead of centralized data teams managing the entire lake, Data Mesh advocates for domain-oriented teams owning, managing, and serving their data as ‘data products,’ fostering greater accountability and agility.
- Decentralized Governance: While there are global standards, individual domains have autonomy over their data.
- Self-Service Data Platform: A platform that provides tools and infrastructure for domain teams to easily create, publish, and consume data products. Data Lakes will become a component within this broader, decentralized data ecosystem.
E. AI-Driven Data Optimization and Automation
AI will increasingly optimize the Data Lake’s internal operations.
- Automated Data Tiering: AI algorithms will automatically move data between hot, warm, and cold storage tiers based on access patterns to optimize costs and performance.
- Intelligent Indexing and Caching: AI will predict query patterns and automatically create or update indexes and caches for optimal query performance.
- Autonomous Data Pipelines: AI-driven data pipelines that can self-heal, scale dynamically, and optimize their execution plans based on real-time data characteristics and workload demands.
Conclusion
In the contemporary business landscape, data is unequivocally the most valuable asset, and Data Lakes are the essential architecture for harnessing its immense power. By providing a scalable, flexible, and cost-effective repository for all forms of raw data, Data Lakes enable organizations to move beyond mere reporting to unlock massive, hidden insights through advanced analytics, machine learning, and AI. They represent a fundamental shift from rigid, predefined data schemas to a dynamic, ‘schema-on-read’ approach, empowering data scientists and analysts to explore information with unprecedented freedom.
While the journey of implementing and governing a Data Lake presents its own set of challenges—from ensuring data quality and security to bridging skill gaps and managing complex tool ecosystems—the transformative benefits it offers in terms of comprehensive insights, extreme scalability, cost efficiency, and accelerated innovation are undeniable. Looking ahead, the evolution towards Data Lakehouses, AI-driven governance through Data Fabrics, real-time streaming capabilities, and decentralized Data Mesh paradigms will further amplify their impact. Data Lakes are not just storage; they are the living, breathing engines of data-driven growth, continually fueling business agility and competitive advantage by truly unleashing the massive insights that define tomorrow’s successful enterprises.







{kind=link}